
The Data Agent Stack - Part 3: Context Assembly for Data Agents
Why the hard part is not the model call, it’s what you put in front of it

A user asks:
“Why did weekly active usage dip after the launch?”
The agent finds a canonical metric definition, an older dashboard query, a human annotation about test tenants, a launch document, a stale incident note, a saved correction, and a live check showing that one data partition is delayed.
Every source is relevant.
They are not equally authoritative. They are not equally fresh. They do not have the same scope. Some of them disagree.
The hard problem is not generating SQL.
The hard problem is deciding what evidence the model should reason over before it generates the SQL.
A data agent does not reason over the organization’s warehouse, catalog, semantic layer, documents, and history as one coherent system. It reasons over a bounded evidence bundle assembled for the current turn.
Reliability depends on how that bundle is retrieved, permission-filtered, ranked, reconciled, compressed, placed, and inspected.
Part 1 established that a data agent is a governed analysis loop, not text-to-SQL.
Part 2 established that the platform must make meaning, ownership, freshness, lineage, canonical status, and quality visible.
Part 3 explains how those available signals become model-visible evidence for one question.
The model does not reason over your data platform. It reasons over the evidence boundary you construct for this turn.
The Model Sees a Constructed World
The model does not see the warehouse as a coherent system.
For each model call, the runtime constructs a payload from selected representations and observations.
That payload may contain:
System instructions
The user’s question
Conversation state
Tool definitions
A resolved metric, entity, and time range
Selected semantic definitions
Selected table descriptions
Retrieved documents
Applicable memories
Live tool outputs
It helps to separate two related terms.
Context is the complete payload assembled for a model call. It includes instructions, history, tools, evidence, memory, and runtime observations.
The evidence bundle is the factual subset of that payload used to answer the data question.
This post focuses on how that evidence bundle gets built.
Prompt engineering mainly concerns instructions. Context engineering concerns the dynamic construction of the full model request, including external knowledge, memory, conversation state, and tool outputs.
Context assembly is also broader than RAG.
RAG supplies retrieved evidence. Modern retrieval systems may include query rewriting, filters, reranking, and compression.
A production context-assembly system must also decide:
Which retrievers should run
Whether the current user is allowed to receive each result
What claim each result can support
Whether a stronger source supersedes it
Whether the fact is current enough
Whether it belongs in initial context or should be checked live
How much space it deserves
Where it should appear in the model request
How the final selection can be reconstructed later
The distinction I draw here is architectural: RAG supplies retrieved evidence, while context assembly also governs permissions, source authority, conflicts, placement, runtime reassembly, and reconstructability.
The semantic layer is also an input to context, not the context layer itself.
A semantic layer can own durable contracts for metrics, dimensions, entities, and valid relationships. For example, MetricFlow defines and manages metric logic and handles SQL query construction.
That makes the semantic layer a strong authority for defined metric meaning.
It does not contain every launch note, incident, user correction, or current partition state that an analytical question may require.
The same boundary applies to the catalog and memory.
The catalog owns durable asset metadata.
The semantic layer owns governed business definitions.
Memory owns persisted, scoped corrections or reusable state.
Runtime context contains observations made during the current analysis.
Context assembly selects from all of them.
My read is that the evidence bundle behaves like a permission-scoped, per-query materialized view of organizational knowledge.
It is generated for one question. It is bounded. It is not the canonical system of record. It can contain uncertain or conflicting evidence, and it may change after live verification.
Calling it the “control plane for correctness” would create unnecessary category confusion.
The formal agent control plane owns routing, session identity, state ownership, and policy attachment.
Context assembly is better described as the evidence boundary for the turn.
From a Question to Candidate Evidence
Most descriptions of context assembly jump directly to retrieval.
That skips the first system decision.
Before searching for tables, documents, or prior queries, the runtime should resolve the shape of the question:
Which metric?
Which entity?
Which population?
Which time range and timezone?
Which comparison period?
Which launch or event?
Which breakdown?
Which analytical task?
Which terms remain ambiguous?
For the weekly-usage question, “weekly active usage,” “the launch,” and “after” may all require resolution.
A retriever cannot compensate for a badly formed question envelope. It will return relevant evidence for the wrong interpretation.
Candidate generation should then be broad, cheap, and source-aware.
Different sources require different retrieval methods:

One search query should not be sent blindly to every source.
A metric identifier may need exact lookup.
An internal codename may need lexical search.
A launch explanation may require semantic document retrieval.
A candidate table may need lineage expansion.
A user correction must be retrieved inside the correct personal or team scope.
This first stage should optimize for recall without pretending that every candidate belongs in model context.
Candidates still need authorization, source arbitration, deduplication, conflict handling, and budgeting.
The full hot path looks like this:
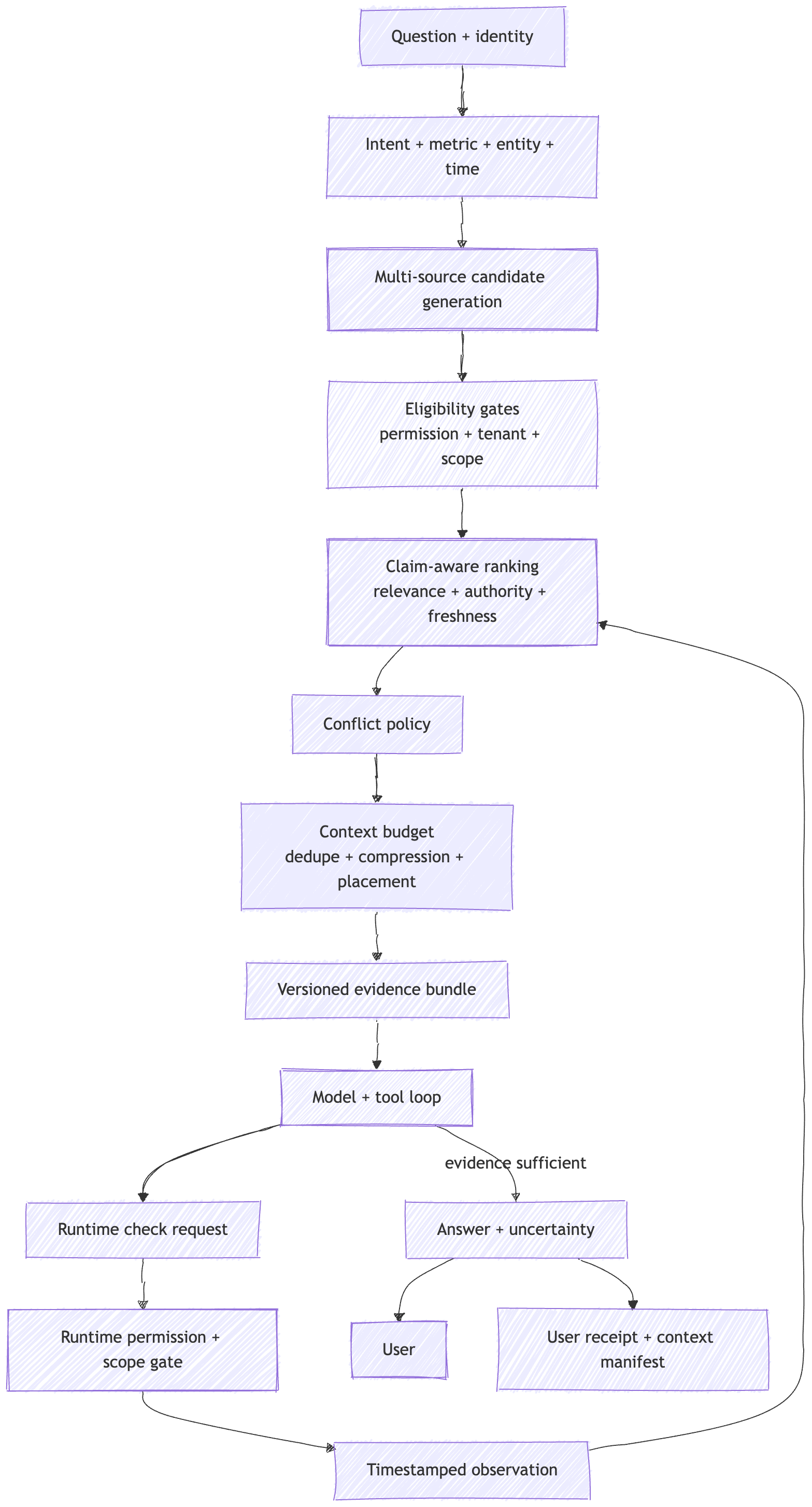
This diagram has two important loops.
First, candidate generation does not send raw results directly to the model.
Second, runtime observations re-enter the same permission, ranking, conflict, and budget path. A live query result should not become trusted context merely because it came from a tool.
Retrieval finds candidates. Authority decides which candidates are allowed to govern the answer.
Retrieval Is an Authority Decision
Semantic similarity answers one question:
Does this source appear related?
It does not answer:
Should this source define the metric?
Permission and scope should be eligibility gates, not weak ranking features. If the current user cannot access a document, table, memory, or derived summary, that evidence should not reach the model.
Among eligible candidates, the system still needs to reason across several dimensions:

Do not collapse these dimensions into one universal score.
Authority depends on the claim being resolved.
A metric contract can define weekly active usage.
A live warehouse check can establish whether the latest partition arrived.
A launch document can establish the rollout date and intended population.
A reviewed incident report can explain telemetry loss during a specific period.
A historical query can reveal join precedent.
A personal memory can express a user-specific analytical preference.
None of these sources has universal authority.
A useful evidence record should therefore preserve more than text:
source_id
source_type
claim_type
authority_class
scope
observed_at
effective_from
effective_to
permission_decision
confidence
derived_from
supersedes
retrieval_reason
source_pointerThese fields allow the assembly layer to compare evidence at the claim level.
Return to the weekly-usage question.
The canonical metric contract should define weekly active usage.
The older dashboard query can supply table and join precedent. Its filter should not silently override the current contract.
The human annotation about test tenants should be included if it applies to the selected dataset, population, and period.
The launch document should establish the launch date and rollout scope.
The stale incident note should remain a hypothesis until its effective period and current relevance are checked.
The saved correction about internal accounts should be applied only inside its valid scope. A personal memory must not redefine a global metric.
The delayed partition check is current evidence that the observed dip may be partly or entirely a data-completeness artifact.
A safe answer would separate observed data state from the behavioral hypothesis:
The current decline cannot yet be separated from delayed telemetry. The analysis used the canonical weekly-active definition and the applicable account exclusions, but one relevant partition remains incomplete. The behavioral conclusion is provisional until the partition is backfilled or the comparison is restricted to complete periods.
That is more useful than confidently attributing the decline to the launch.
Conflict is not always a retrieval failure.
Sometimes conflict is the correct state of the evidence.
The system needs explicit outcomes:
Retain: Keep both claims with their scopes.
Supersede: Select one source and record why it replaced another.
Verify: Run a bounded live check.
Clarify: Ask the user which definition or population applies.
Abstain: Return insufficient evidence.
Silently selecting the nearest embedding is not a conflict policy.
Prepared Evidence Gives Speed, Live Verification Gives Currency
A production data agent usually draws from two operational paths.
Prepared evidence is indexed or computed before the question arrives.
Live verification is performed during the analysis.
The data-agent case study from OpenAI describes six context layers: table usage, human annotations, code-derived enrichment, institutional knowledge, memory, and runtime context.
These layers are a useful public case study, not a universal taxonomy.

A semantic layer belongs alongside these sources as a durable business contract. It may provide stronger authority for defined metrics than any retrieved document or historical query.
Memory needs special handling.
Memory is durable state persisted outside the model and re-injected into later turns. It is not a model-weight update.
A data-agent memory might contain:
A confirmed filter correction
A user or team preference
A reusable constraint
A non-obvious encoding rule
A past analytical decision
Two properties make memory easy to misuse: scope and age.
A personal correction should not cross into team or global context.
An old memory should not silently override a newer metric contract.
An inferred memory should not carry the same confidence as an explicit user instruction.
Runtime observations solve a different problem.
A catalog description may say a table updates hourly.
A live partition check can establish whether it updated this hour.
A document may say an incident was resolved.
A current workflow check can establish whether the affected pipeline is healthy now.
A runtime observation is strong evidence for the fact it measured, at the recorded timestamp and scope.
It does not have universal authority.
A live query can establish that a partition is delayed.
It cannot redefine weekly active usage.
The boundary looks like this:
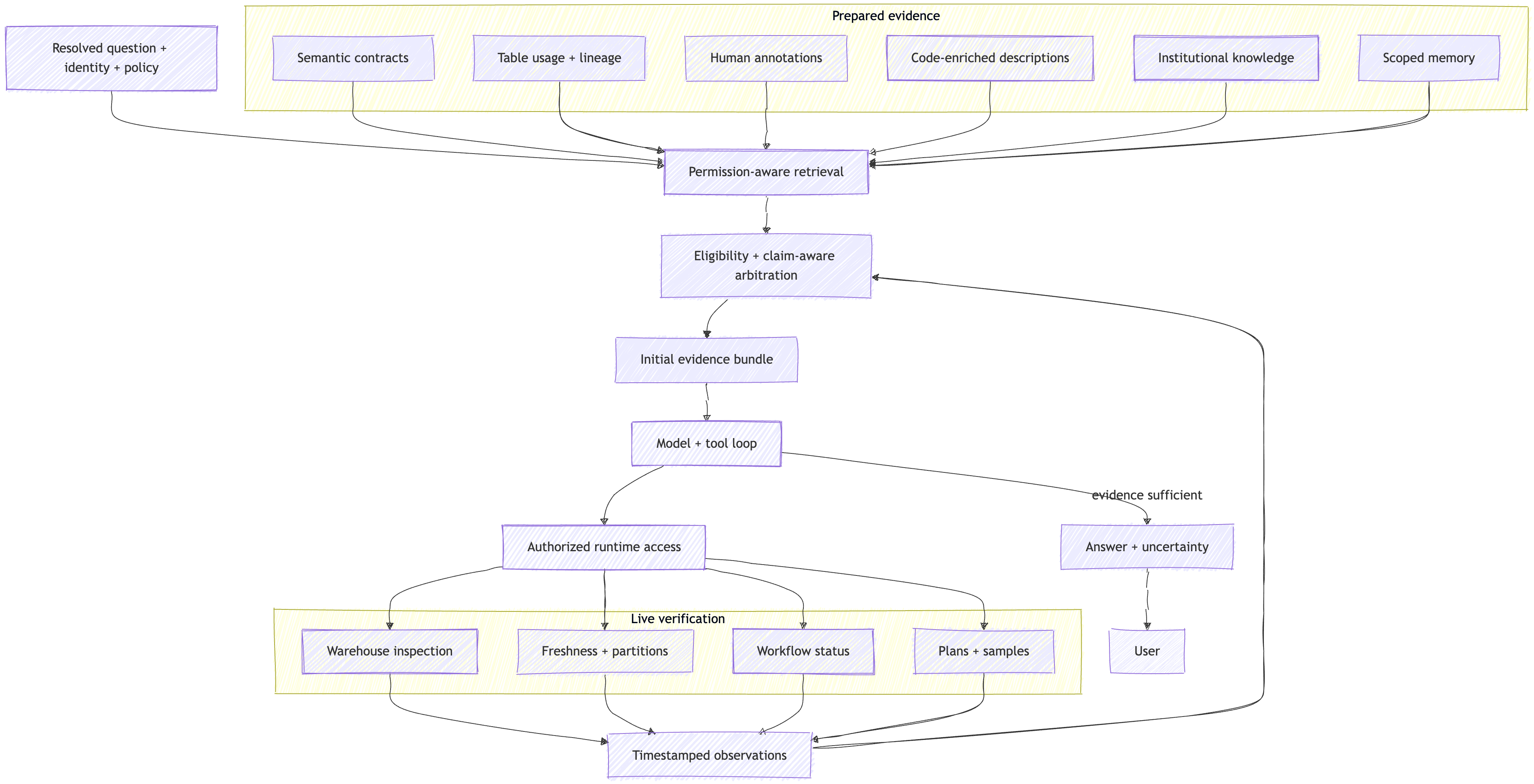
Prepared evidence gives the agent a fast starting point.
Live verification establishes what is true now.
The important detail is the return path. Runtime observations go back through eligibility and arbitration before they become model-visible evidence.
More Context Is Not Better Context
Candidate retrieval and final context have different goals.
Candidate retrieval needs enough recall to avoid missing the governing evidence.
The final bundle needs enough precision to avoid burying that evidence.
That difference creates a context budget.
The budget includes:
Input tokens
Retrieval latency
Reranking latency
Retrieval fan-out
Tool-call latency
Warehouse cost
Model cost
Space reserved for runtime results
Attention dilution
User-facing response time
Even when the model supports a large context window, the hot path is not free.
More material creates more opportunities for:
Redundancy
Contradiction
Stale context
Weak precedent
Lost qualifiers
Irrelevant evidence
Higher latency
Higher cost
Long-context research has shown that the presence of relevant information does not guarantee reliable use of that information. In evaluated models and tasks, performance could vary significantly depending on where relevant evidence appeared inside the input.
The operational lesson is simple.
“Retrieve everything” is not a production strategy.
Context assembly requires exclusion, compression, and placement.
Useful operations include:
Deduplicating repeated descriptions
Grouping evidence by claim
Removing superseded sources
Preserving conflicting sources when the conflict remains unresolved
Compressing documents while retaining source pointers
Reserving space for runtime observations
Placing canonical contracts and critical caveats prominently
Dropping weak historical precedent before dropping metric contracts or owner-approved definitions
Compression creates its own failure mode.
Suppose a source says:
Exclude internal accounts only for the external-adoption view.
A lossy summary might become:
Exclude internal accounts.
The summary is shorter.
It is also wrong outside the original scope.
Compression must preserve the fields that determine how a claim should be trusted:
Claim
Scope
Authority
Effective period
Confidence
Provenance
The system must also decide what belongs in the initial bundle and what should be fetched later.
Initial evidence should usually contain stable, high-authority material:
Question interpretation
Metric contract
Small candidate-table set
Known caveats
Applicable memory
Permission constraints
Known conflicts
Just-in-time evidence should handle volatile or expensive facts:
Current partitions
Live schema inspection
Distinct values
Samples
Workflow status
Query plans
Actual query results
A useful context budget is not:
Fill the window with the best material available.
It is:
Include the minimum evidence needed to make the next safe analytical decision.
Persist the Context Manifest
A query link proves what ran.
It does not prove why that query was selected.
Part 1 introduced the user-facing receipt:
The interpreted question
Metric definition
Tables
Filters
Executed query
Results
Assumptions
Caveats
Permission fallbacks
Part 3 needs an operator-facing artifact behind that receipt: the context manifest.
A query link proves what ran. A context manifest proves why it ran.
A useful manifest should preserve:
A stable manifest identifier
Question interpretation
Candidate source identifiers
Source versions and retrieval timestamps
Permission and scope decisions
Ranking or reason codes
Rejected candidates
Superseded candidates
Compression and transformation lineage
Final evidence ordering
The exact serialized bundle, or an immutable hash with retained source snapshots
Bundle versions before and after runtime verification
Tool outputs and observation timestamps
Model, prompt-template, and tool-schema versions
Remaining conflicts and uncertainty
The final answer
This does not require exposing private chain-of-thought.
It requires exposing system inputs, evidence transformations, and consequential policy decisions.
The runtime flow should leave a durable record at each material transition:
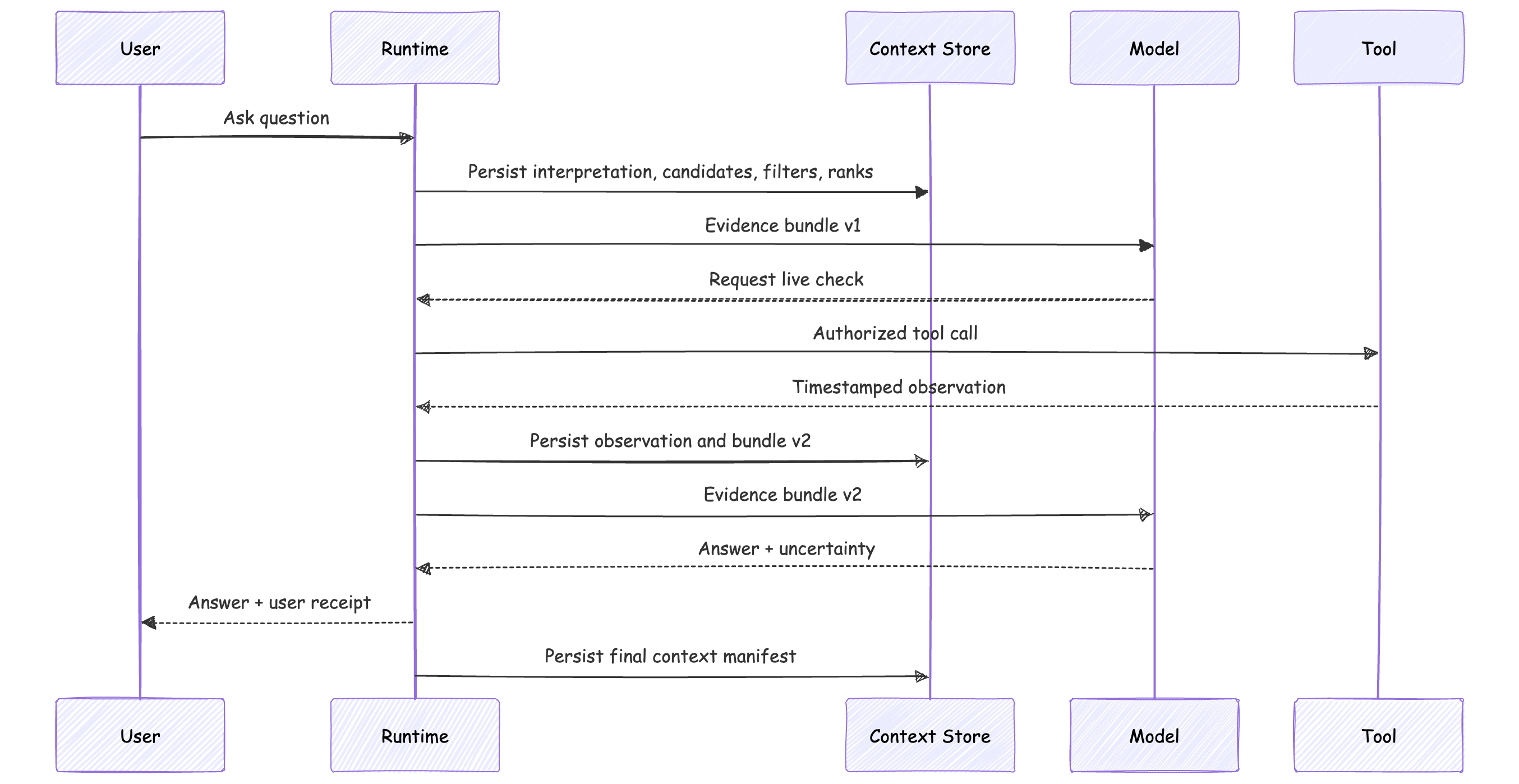
At 3:00 AM, the operator should be able to answer:
Which metric definition was injected?
Which retrievers ran?
Which candidates were denied?
Which dashboard query was retained as precedent?
Which source was superseded?
Which memory was applied, and at what scope?
Which runtime observation changed the plan?
What exact evidence did the model receive in each bundle version?
Without that manifest, two runs can produce different answers and still look individually reasonable.
The divergence is visible.
The cause is not reproducible.
How Context Assembly Fails
1. Question decomposition misses the governing term
Symptom: The system retrieves evidence for the wrong definition of “weekly active usage.”
Why it still looks plausible: The candidate tables and columns use similar names.
Control: Resolve metric, entity, population, time range, and event before broad retrieval. Ask when ambiguity remains material.
2. Over-retrieval buries the contract
Symptom: Repetitive dashboard queries consume most of the bundle while the canonical definition appears once.
Why it still looks plausible: Many sources appear to agree.
Control: Allocate budget by evidence class, deduplicate precedent, and reserve prominent placement for governed contracts and unresolved conflicts.
3. Popularity becomes authority
Symptom: A widely copied query with an outdated filter outranks the current metric contract.
Why it still looks plausible: Repeated successful execution looks like validation.
Control: Treat query history as precedent by default. Require ownership, certification, recency, and canonical status before promoting it.
4. Stale context defeats live evidence
Symptom: An old incident note says telemetry is healthy while the latest partition is delayed.
Why it still looks plausible: The incident document contains a specific and convincing explanation.
Control: Attach effective periods to offline evidence and require live verification for volatile operational claims.
5. Memory crosses scope
Symptom: One user’s correction becomes a global analytical rule.
Why it still looks plausible: The correction improved a previous answer.
Control: Require explicit memory scope, distinguish confirmed from inferred memories, and compare memory against current canonical definitions.
6. Permission filtering happens too late
Symptom: A restricted document or runtime result reaches the model before access control is applied.
Why it still looks plausible: The final prose may omit the sensitive detail.
Control: Apply authorization before every model exposure, including initial retrieval, live tool outputs, derived summaries, and persisted manifests.
7. Provenance disappears during compression
Symptom: Several documents become one clean summary with no traceable claim-to-source mapping.
Why it still looks plausible: The summary is concise and internally consistent.
Control: Preserve source identifiers, versions, scope, effective periods, and transformation lineage through every compression step.
8. Source conflict is flattened
Symptom: A metric contract and owner annotation disagree, but the bundle presents one interpretation as settled.
Why it still looks plausible: The conflict disappeared before the model reasoned over it.
Control: Represent disagreement explicitly and define retain, supersede, verify, clarify, and abstain outcomes.
Builder Checklist
Inventory every context source.
Identify what comes from semantic contracts, catalog context, table usage, annotations, code, documents, memory, and live tools.Define source-specific retrieval.
Specify when to use exact lookup, semantic retrieval, structured filters, query-pattern search, or lineage traversal.Assign authority by claim type.
Decide which source defines metrics, launch timing, table caveats, current freshness, and user-specific preferences.Enforce permission and scope before every model exposure.
Apply the same rule to initial retrieval, memory, documents, live observations, derived summaries, and manifests.Separate prepared evidence from live verification.
Use prepared evidence for speed. Use live checks for volatile state, missing metadata, and unresolved conflicts.Preserve provenance through transformation.
Every included claim should retain a source pointer, source version, effective period, scope, and retrieval timestamp.Enforce a context budget.
Budget tokens, retrieval fan-out, latency, warehouse cost, and space for runtime observations.Persist the bundle and define failure behavior.
Record included, rejected, and superseded evidence. Decide when the agent should verify, clarify, disclose competing interpretations, or return insufficient evidence.
Recap
The data foundation determines which signals exist.
Context assembly determines which signals the model sees now, under whose authority, and with what uncertainty.
That selection is where relevance, authority, freshness, scope, permissions, latency, and cost become one operational decision.
The model does not reason over the whole data platform.
It reasons over a mediated, bounded representation of that platform.
When the assembled evidence is wrong, a capable model can still produce a polished wrong answer.
When the evidence boundary is explicit, permission-aware, bounded, and reconstructable, the agent has a better chance of knowing both what to answer and when the available evidence is not strong enough to answer.
What Comes Next
Next, I’ll go deeper on one of the most important context sources: pipeline code.
Schemas describe shape.
The code that produces a table often reveals its grain, filters, exclusions, freshness, and intended use.
Part 4: Meaning Lives in Code
Where does context assembly break first in your system: candidate generation, source authority, freshness, permissions, memory scope, or live verification?