
The Data Agent Stack - Part 1: What Is a Data Agent?
Why a data agent is not just text-to-SQL

Most data-agent demos start with a simple promise:
Ask a question in English.
Get an answer from your warehouse.
That is useful.
But it is not the hard part.
The hard part is knowing what the question means, which data is trusted, what the user is allowed to see, whether the result is fresh, and how to prove where the answer came from.
A data agent is not a SQL generator.
It is a governed analysis loop that turns an ambiguous data question into a verified answer with evidence.
Text-to-SQL is one capability inside that loop. It matters. It is just not the system.
Imagine a leader asks:
“Why did revenue dip last week?”
The agent returns a chart and a clean paragraph.
The SQL ran.
The numbers look plausible.
The answer sounds confident.
Then Finance asks: which revenue definition did it use? Did it include refunds? Was the table fresh? Did it use booked revenue or recognized revenue? Was the user allowed to see the underlying rows?
If the answer cannot show that path, the system did not produce analysis.
It produced prose over a query.
Text-to-SQL writes a query. A data agent has to prove the answer.
The public OpenAI post on its in-house data agent is a useful case study because it frames the problem this way. It describes a custom internal-only tool built around OpenAI’s own data, permissions, and workflows, where the agent handles analysis end to end: understanding the question, exploring data, running queries, and synthesizing findings.
My read is simple: the interesting part is not that a model can write SQL.
The hard part is the system around the SQL.
Text-to-SQL is a capability, not the system
Text-to-SQL answers one question:
Can the model produce a query from natural language?
That is useful. It saves time. It lowers the barrier for people who understand the business question but do not know the warehouse schema.
But production data work rarely starts with a perfectly specified question.
A user asks:
“What happened to revenue last week?”
The system still has to decide what “revenue” means.
Booked revenue? Recognized revenue? Net revenue? ARR? Product usage revenue? Finance’s metric? Growth’s metric? A dashboard definition? A one-off analysis definition?
It also has to decide what “last week” means.
Calendar week? Fiscal week? Trailing seven days? Which timezone?
Then it has to choose the right data.
Which table is canonical? Which one is stale? Which one includes test traffic? Which one excludes logged-out users? Which one was deprecated but still appears in historical queries?
Then it has to decide whether the user is allowed to see the underlying data.
Only after those questions does SQL generation become the central act.
This is why “chat with your warehouse” is too small as a mental model.
A warehouse does not contain meaning by itself. It contains tables, columns, partitions, rows, and sometimes comments.
Meaning lives across more surfaces: metric definitions, table ownership, lineage, dashboards, pipeline code, docs, incident notes, Slack threads, notebooks, and repeated human usage.
The OpenAI post makes this point in its discussion of context. It says high-quality answers depend on rich, accurate context, and names multiple context layers: table usage, human annotations, code enrichment, institutional knowledge, memory, and runtime context.
A data agent assembles those pieces into a working set, acts through tools, and returns an answer with proof.
Text-to-SQL is inside that system.
It is not the system.
A data agent is a governed analysis loop
The simplest useful picture is this:
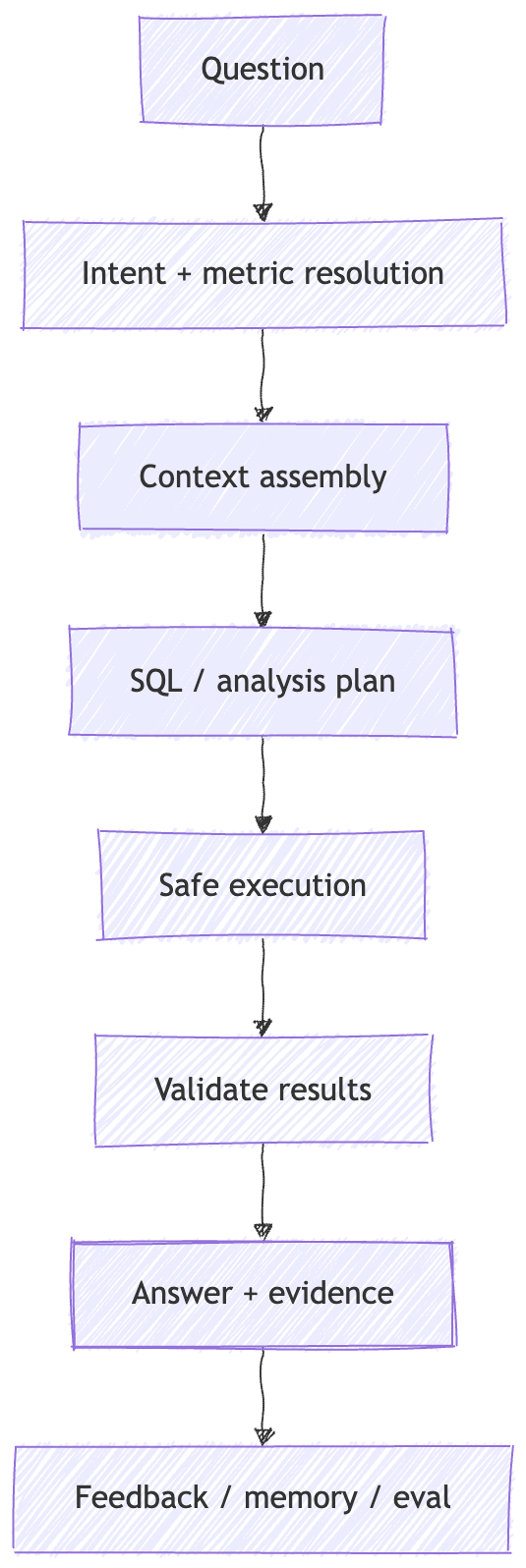
Each box owns a different failure mode.
Question is where the event enters. It may come from Slack, a web UI, an IDE, a notebook, a dashboard, a CLI, or an API. The interface matters for workflow, but it is not the agent.
Intent and metric resolution is where ambiguity gets handled. The system has to infer or ask: what metric, cohort, time range, entity, grouping, and business definition are being requested?
Context assembly is where the system gathers the working set for this turn: table descriptions, metric definitions, lineage, trusted query examples, human annotations, docs, memory, and runtime facts.
SQL or analysis plan is where the model proposes the next analytical move. Sometimes that move is SQL. Sometimes it is schema inspection, freshness checking, a clarifying question, a dry run, a sample query, or a notebook/report step.
Safe execution is where the system acts under constraints: permissions, row limits, timeouts, cost budgets, tool scopes, audit logs, and redaction.
Validation is where the system checks whether the result makes sense. Did the query return zero rows? Did the join explode? Did null handling change the answer? Does the result match an expected range? Did the query answer the question that was actually asked?
Answer with evidence is where the user gets the result, but also the receipt: tables used, assumptions, filters, executed query, result links, caveats, and permission fallbacks.
Feedback, memory, and eval is where the system improves. A correction should not vanish into the transcript. It should become memory, documentation, a semantic-layer fix, a table annotation, or a regression test.
ByteByteGo’s OpenAI data agent article describes a similar shape from the user side: the agent figures out relevant tables, writes SQL, runs it, checks the result, and returns an answer with reasoning attached. It also frames the system as an LLM plus a harness: the model reasons, while the harness provides tools, context, and the loop that lets it act and observe.
That observe step matters.
A one-shot SQL generator can produce a query.
A data agent can run the query, inspect the result, notice something looks wrong, and try again. The OpenAI post gives this as an explicit behavior: if an intermediate result looks wrong, such as a zero-row result caused by an incorrect join or filter, the agent investigates, adjusts, and retries while carrying context forward.
That is the difference between answering and analyzing.
The hard part is meaning
Most bad data answers are not caused by syntax errors.
They come from meaning errors.
The query uses the wrong table.
The metric name maps to the wrong definition.
The table has the right column but the wrong population.
The dashboard query was copied without its original assumptions.
The data is stale.
The join is legal but semantically wrong.
Data ambiguity usually hides in three places: the metric, the entity, and the time window.
Metric ambiguity: what does “revenue” mean?
Entity ambiguity: what is a “user,” “account,” “workspace,” or “customer”?
Time ambiguity: what does “last week” mean?
A good data agent should either resolve those from context or ask before it pretends the question is clear.
This is why schemas are not enough.
A schema tells you shape.
It tells you that a table has user_id, created_at, country, and revenue_amount.
It does not tell you whether user_id means account user, workspace user, seat, device, lead, or billing contact.
It does not tell you whether revenue_amount is gross, net, recognized, booked, refunded, or test-adjusted.
It does not tell you whether the table excludes internal traffic, delayed events, deleted accounts, or late-arriving rows.
That information lives elsewhere.
Some of it lives in a semantic layer: metrics, dimensions, entities, measures, filters, and business definitions.
Some of it lives in lineage: upstream jobs, downstream consumers, data movement, and transformation history.
Some of it lives in catalog context: owners, descriptions, tags, glossary terms, freshness, criticality, and usage.
Some of it lives in code.
This is the part many systems miss. Schemas and query history describe a table’s shape and usage. Pipeline logic often explains what the table means: grain, filters, exclusions, freshness guarantees, and business assumptions.
Part 4 will go deep on that idea.
For Part 1, the point is simpler:
A data agent cannot rely on schema alone.
It needs context that makes the data legible before the model reasons over it.
Context assembly is not “retrieve everything.” It is selecting the smallest useful evidence set for the turn.
For a data agent, the payload is not chat history.
It is the evidence bundle for analysis.
A data agent returns an answer with a receipt
A fluent answer is not enough.
For a data agent, the answer has to come with a receipt.
At minimum, the user should be able to inspect:
what question the system thought it was answering
what metric definition it used
what tables it selected
what filters it applied
what SQL or analysis steps ran
what results came back
what assumptions were made
what caveats apply
what data the user was not allowed to access
what evidence supports the final answer
This is not only for user trust.
It is for debugging.
At 3:00 AM, the operator does not need a beautiful explanation. They need to know what happened.
Which query ran?
Which table did it hit?
Which context did the model see?
Which permission path was used?
Which validation checks passed?
Which ones did not run?
Was the answer based on live data, cached context, memory, or a stale doc?
A query without provenance is just an opinion with SQL attached.
Provenance is the answer’s receipt: tables, SQL, assumptions, results, timestamps, and permissions.
The OpenAI post makes this trust boundary explicit. It says the agent plugs into the existing security and access-control model, operates as an interface layer, and uses strict pass-through access so users can only query tables they already have permission to access. It also says the agent links to underlying results and summarizes assumptions and execution steps so users can inspect the raw data and verify the analysis.
That is the right shape.
A data agent should not create new authority just because the interface is conversational.
“Can answer” must be downstream of “is allowed to know.”
Permission checks should apply to the warehouse, the documents, the retrieved context, and the final summary.
The same applies to evaluation.
String matching is not enough. A generated SQL query can differ from the golden SQL and still be correct. It can also look reasonable and return the wrong result.
The OpenAI post describes evals built from curated question-answer pairs and golden SQL. The generated SQL is executed, the generated results are compared against expected results, and a grader produces a score and explanation.
That is the evaluation shape data agents need.
Not just: did the answer sound good?
But: did the system produce the right result, from the right data, using the right assumptions, under the right permissions, with enough evidence to prove it?
SQL correctness is local. Answer correctness is end-to-end.
The stack behind the answer
Part 1 is the map, not the whole journey.
But it helps to name the layers early.
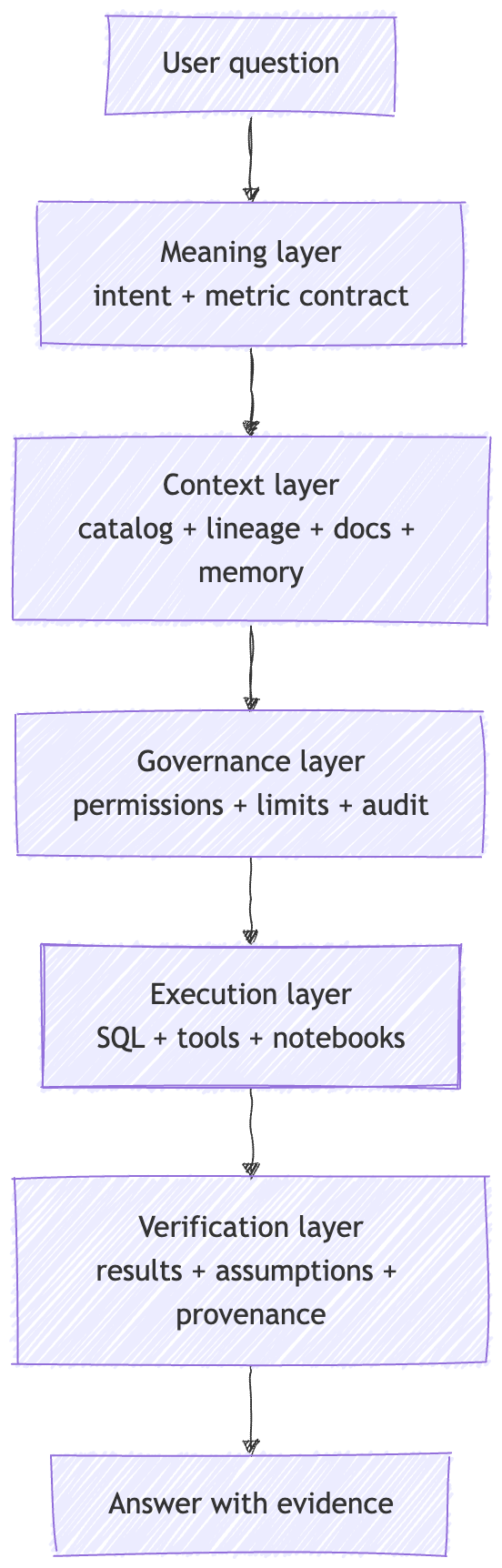
A production data agent has to coordinate five broad layers.
Meaning layer. What is the user actually asking? Which metric, entity, cohort, time range, and business definition apply?
Context layer. Which evidence should the model see? This includes semantic definitions, catalog metadata, lineage, human annotations, code-derived meaning, institutional knowledge, memory, and runtime checks.
Governance layer. What is the agent allowed to see and do? This includes pass-through permissions, policy enforcement, row and column security, redaction, audit, and data isolation.
Execution layer. Which tools can the agent use? This includes SQL execution, metadata lookup, notebook/report generation, orchestration inspection, and platform checks.
Verification layer. How does the system know the answer is acceptable? This includes SQL checks, result comparison, sanity checks, assumptions, provenance, golden questions, and regressions.
My read is that this is why data agents are a natural bridge between data infrastructure and agent infrastructure.
The model matters.
But the model is not the source of truth.
The data platform determines what the model can know, what it can do, what it is allowed to see, and whether anyone can trust the answer.
Failure modes
Here are the failure modes I would keep in your head for the rest of the series.
1. Correct SQL, wrong table
The query is syntactically correct.
The result returns.
The answer sounds plausible.
But the agent selected a table with the wrong grain, stale data, excluded population, or deprecated semantics.
This is the classic data-agent trap: correctness at the SQL layer, failure at the meaning layer.
2. Right metric name, wrong definition
The user asks for “revenue,” “active users,” “retention,” or “conversion.”
The agent silently picks a definition.
No clarification.
No metric contract.
No caveat.
The answer may be internally consistent, but it is not necessarily the answer the user asked for.
3. Fast answer, no evidence trail
The system returns a clean paragraph.
But there is no query link, table list, assumption summary, freshness check, permission note, or result artifact.
This is fine for a demo.
It is weak for production.
4. One-shot query when the task required exploration
Some questions are simple lookups.
Many are not.
A dip, anomaly, launch readout, cohort comparison, or funnel diagnosis usually requires iteration: inspect candidate tables, check freshness, run intermediate queries, validate joins, and revise the plan.
If the system treats every question as one SQL query, it will miss the work analysts actually do.
5. Permissions treated as an afterthought
The agent retrieves context or runs a query before checking whether the user should see the data.
This is backwards.
Permissions are not a final filter on the answer. They are part of the execution path.
Builder checklist
If you are building or evaluating a data agent, start here.
Define what “verified answer” means.
Decide what evidence must exist before the system can answer.Separate SQL generation from answer synthesis.
Writing the query is not the same as proving the answer.Require query and result provenance.
Track the query, tables, filters, time window, result artifact, and execution status.Surface assumptions in the answer.
Make metric definitions, default time ranges, filters, and caveats visible.Resolve permissions before retrieval and execution.
The agent should act with the user’s authority, not a silent superpower.Treat context sources as ranked evidence.
Schema, lineage, docs, query history, memory, and runtime checks do not all carry the same authority.Turn corrections into durable system improvements.
A correction should become memory, a catalog update, a semantic-layer fix, or an eval.Evaluate results, not just text.
Data-agent evals should check SQL, result sets, assumptions, provenance, and permission behavior.
Recap
A data agent is not text-to-SQL with a nicer interface.
Text-to-SQL writes a query.
A data agent resolves meaning, assembles context, executes under constraints, validates the result, enforces permissions, and returns evidence.
That is the stack.
A chatbot can answer a question.
A data agent has to prove the answer.
What comes next
In Part 2, I’ll go one layer lower: the data foundation.
A coding agent usually starts with a repo.
A data agent starts with organizational entropy: tables, pipelines, dashboards, docs, Slack threads, metric definitions, ownership, freshness, lineage, and permissions.
No agent architecture can fully hide a messy data foundation.
It just makes the mess conversational.
The Data Agent Stack
Part 1: What Is a Data Agent?
Part 2: The Data Foundation Is the Agent
Part 3: Context Assembly for Data Agents
Part 4: Meaning Lives in Code
Part 5: Tools, Query Execution, and the Analyst Loop
Part 6: Trust, Permissions, and Governance
Part 7: Evals, Provenance, and Production Feedback Loops
References
ByteByteGo, How OpenAI Built Its Data Agent
Google Cloud, A dev’s guide to production-ready AI agents
dbt, About MetricFlow
OpenLineage, About OpenLineage
DataHub, The Metadata Model
If you are building this kind of system, I’d be curious where it breaks first for you: metric definitions, table discovery, permissions, query validation, provenance, or something else.
My own bet: most systems break first at the meaning layer.
Not because the SQL is impossible, but because “revenue,” “active user,” “customer,” or “last week” often means different things across teams.
Table discovery and query validation matter too, but if the metric definition is ambiguous, everything downstream becomes shaky.
Curious where others have seen the first real break: metric meaning, table discovery, permissions, validation, provenance, or something else?