
The Data Agent Stack - Part 2: The Data Foundation Is the Agent
Why no agent architecture can save messy data

A coding agent starts with a repo.
A data agent starts with organizational entropy.
The user asks, “What was weekly active usage after launch?”
The platform has five plausible tables, three similar columns, two dashboards, one stale doc, and no visible owner.
The model will still answer.
That is the problem.
Part 1 made the first cut: a data agent is not text-to-SQL. It is a governed analysis loop. It resolves meaning, finds trusted data, executes safely, validates results, enforces permissions, and returns evidence.
Part 2 goes one layer lower.
Before the agent can assemble good context, the data platform has to make meaning visible.
A data agent inherits the shape, quality, and governance of the data platform underneath it.
A better model can write cleaner SQL.
It cannot magically know which table your company trusts.
A data agent does not hide data chaos. It makes the chaos conversational.
The foundation is part of the agent
Most agent diagrams start too high.
They begin with a user question, a model call, a tool call, and a SQL query.
That explains the loop, but it hides the first production dependency.
The agent can only reason over the world the platform exposes.
If the warehouse has five similar tables, the agent has five candidates. If none of them is marked canonical, the agent has to infer authority from weak signals. If a deprecated table is still discoverable, it still looks useful. If freshness is invisible, stale data can look just as valid as current data.
OpenAI’s public post on its in-house data agent makes this concrete. The post says OpenAI’s data platform serves more than 3.5k internal users, spans more than 600 PB, and includes 70k datasets. At that scale, finding the right table can itself become one of the most time-consuming parts of analysis.
The post also calls out similar tables, overlapping fields, and differences such as whether a table includes logged-out users.
That is not a SQL problem first.
It is an authority problem.
The hard part is not writing SQL. The hard part is deciding what the SQL is allowed to mean.
OpenAI’s post also names silent analytical failure modes: many-to-many joins, filter pushdown errors, and unhandled nulls can invalidate results even when a query runs.
That is the scary failure mode for a data agent.
The query does not crash.
The answer sounds reasonable.
The source assumption is wrong.
My read is: the “agent” is not just the model loop. In a production data system, the effective agent includes the catalog, semantic layer, lineage graph, data quality checks, historical query patterns, and governance metadata that shape what the model sees.
If those systems are weak, the model inherits the weakness.
If you remember one diagram from this post, make it this one:
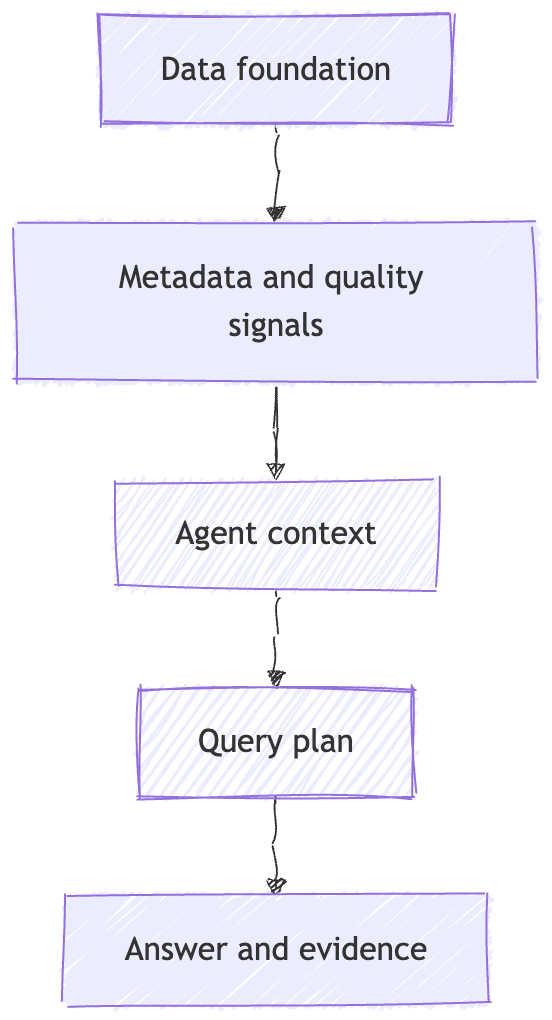
Data foundation quality becomes metadata quality.
Metadata quality becomes context quality.
Context quality shapes query quality.
Query quality shapes answer trust.
Break the chain early, and the rest of the system compensates with guesses.
Schemas describe shape, not authority
A schema tells the agent that a column exists.
It does not tell the agent when to use it.
That sounds obvious until the agent has to choose between revenue, net_revenue, recognized_revenue, bookings, and arr.
The schema can show names and types.
It cannot settle the business definition, the population, the exclusions, the grain, the owner, the freshness expectation, or the caveats.
A schema is not meaning.
It is one hint.
dbt’s model contracts make a useful distinction here. A model contract defines the shape of a returned dataset. dbt’s docs describe contracts as upfront guarantees about model shape, while data tests validate content after the model is built.
That distinction matters for data agents.
A contract can say:
This column exists.
This column has this type.
This model returns this shape.
But the agent still needs to know:
This table is canonical for this metric.
This table is fresh enough for this question.
This column excludes a population.
This join is safe only at this grain.
This dashboard applies a filter that is not obvious from the table name.
This table should not be used for new analysis.
OpenAI’s post says this directly in the data-agent context: metadata alone is not enough. Human annotations capture intent, semantics, business meaning, and caveats that are not easily inferred from schemas or past queries.
The dangerous case is not a missing column.
That usually fails loudly.
The dangerous case is a column that exists, has the right type, has a plausible name, and means the wrong thing.
That is how you get correct SQL and the wrong answer.
Metadata is execution context
Metadata used to be documentation for humans.
A human opened the catalog, read the description, checked the owner, looked at lineage, and decided whether a dataset was safe to use.
A data agent changes that boundary.
Metadata is no longer documentation garnish. It is execution context.
The model does not browse a catalog the way a human does. The runtime retrieves context, ranks it, compresses it, and injects it into the model’s working set.
The answer quality depends on what survives that path.
If descriptions are stale, the agent retrieves stale descriptions.
If ownership is missing, the agent cannot weigh authority.
If lineage is incomplete, the agent cannot see upstream or downstream impact.
If quality checks are not connected to the context layer, the agent may treat a failing dataset as healthy.
If historical queries are not ranked by trust, one-off exploration can become the model’s template.
ByteByteGo’s breakdown is useful secondary interpretation here. It describes OpenAI’s data-agent architecture as a single model, a context assembly layer, curated tools, and a runtime, with much of the reliability coming from the data foundation and context layer rather than an elaborate agent router.
That framing matters.
The model is not confused because it lacks intelligence.
It is confused because the platform has not made authority legible.
If the canonical table is not marked, the model will infer authority from names, examples, and proximity.
Query history is a good example.
A historical query can be a strong signal. It can show how humans join tables, filter data, group metrics, and handle edge cases.
But query history is not neutral.
ByteByteGo reports that embedding all historical queries did not work well because many queries are exploratory one-offs, not canonical patterns. The better pattern was to rank trusted queries higher, especially dashboard-backed, repeated, or data-scientist-authored queries.
That is a data-platform problem.
But once a model uses those examples, it becomes agent reliability work.
Canonical data must be marked, not guessed
Every data platform has canonical datasets.
Many just do not say so clearly.
The canonical table may be known by the data science team. It may be hidden behind a dashboard. It may live in a dbt model description, a Looker explore, a runbook, a Slack thread, or the memory of one staff engineer who has answered the same question for three years.
The agent does not get that context by osmosis.
It needs explicit signals.
Canonical status tells the agent where to go.
Deprecation status tells it where not to go.
The same applies to ownership, grain, primary keys, caveats, freshness, and lineage. These are not catalog niceties. They are decision inputs.
For agent use, a table needs an asset contract:
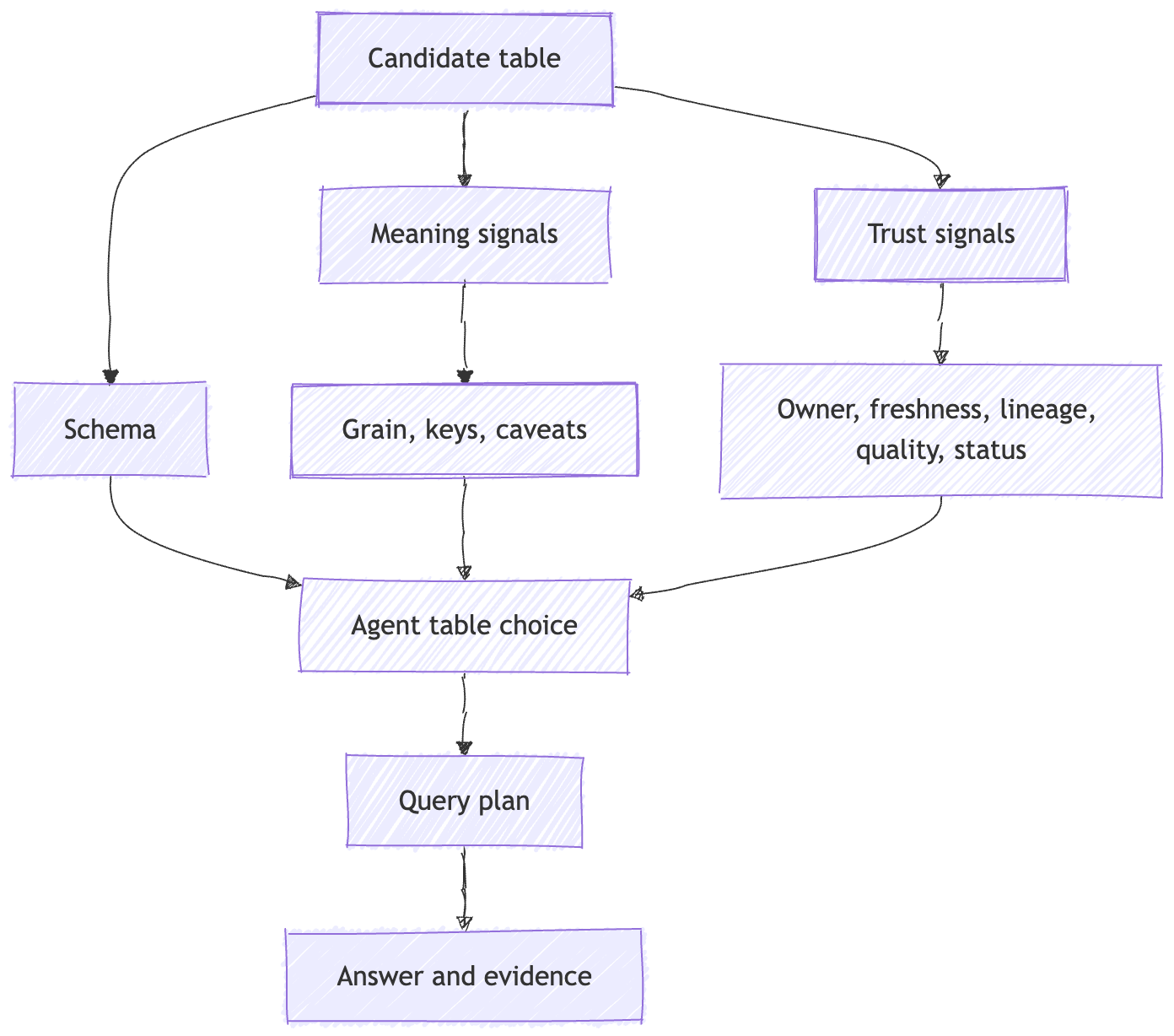
The point is not that every company needs a new formal standard called an asset contract.
The point is simpler.
A table that is safe for agent use needs enough machine-readable context for another system to decide whether it should be used.
Lineage is part of that decision.
Lineage is not just a diagram. It tells the agent what produced the data, what changed upstream, and who depends on it.
For a human analyst, that is debugging context.
For a data agent, it is reasoning context.
Metric definitions need the same treatment.
dbt’s MetricFlow and Semantic Layer docs describe a semantic graph that links language to data through semantic models and metrics. That is the right abstraction for many recurring questions.
Without a metric definition, the agent may find a column called revenue.
With a metric contract, it can find the intended measure, dimensions, entities, filters, and valid paths through the semantic graph.
A metric without a definition is a trap.
A column comment can help retrieval.
It is not a metric contract.
Freshness and quality are answer constraints
Freshness is not a dashboard badge.
It decides whether the answer is valid for the question.
If a user asks about “today,” “this week,” “after launch,” or “current usage,” stale data can invalidate the answer. The agent should not treat a stale table as healthy just because the query runs.
It should know the freshness expectation.
It should know the current freshness status.
It should know whether a failed check should block the answer, warn the user, or route the agent to a different dataset.
Data observability systems commonly track signals such as schema changes, row counts, freshness timestamps, missing values, and distribution shifts. Those signals are useful for humans. They become more important when an agent uses them to decide whether a source is safe.
An anomaly may not mean the answer is wrong.
A failed test may mean the answer should stop.
Either way, the signal has to be visible to the agent.
A failed check in a dashboard the agent cannot see is not an agent guardrail.
My read is: data quality systems, catalogs, semantic layers, lineage systems, and freshness checks are becoming part of the agent reliability stack. They are no longer only back-office governance tools. They are runtime inputs.
A warehouse connector gives the agent access.
The foundation tells it what access is safe to use.
Data platform hygiene becomes agent reliability work when the model uses platform signals to choose.
Failure modes
These are the failures I would look for before trusting a data agent in production.
1. Similar tables with different populations
The agent sees users, active_users, user_accounts, and logged_in_users.
One includes logged-out users. One excludes test traffic. One only covers first-party usage. One feeds an old dashboard.
The schema is close enough that the wrong choice still produces a plausible answer.
2. Freshness is invisible to the agent
The table exists.
The query runs.
The answer looks clean.
But the latest partition is delayed, so the agent reports yesterday’s state as today’s truth.
3. Deprecated tables still appear useful
A table was replaced six months ago.
Humans know not to use it.
The agent still retrieves it because the name is good, the schema matches, and old queries reference it.
4. Historical queries teach bad usage patterns
The agent retrieves a one-off exploratory query and treats it like a trusted template.
This is especially risky when query retrieval does not distinguish production dashboards, repeated patterns, reviewed analyses, and one-time investigations.
5. Schema says a column exists, but not when to use it
A column like user_id might mean actor, account owner, workspace member, billing user, or device user.
The type does not reveal the semantic role.
6. Grain is undocumented
The agent joins an event-level table to a daily aggregate and silently multiplies counts.
The SQL is valid.
The answer is not.
7. Quality checks exist but are not visible to the agent
The data quality system knows a check failed.
The agent’s context layer does not.
The answer proceeds as if the table is healthy.
8. Dashboards are treated as ground truth without provenance
The agent copies a dashboard number without knowing the filters, owner, source table, or metric definition behind it.
Dashboards can be useful evidence.
They are not automatically the source of truth.
Builder checklist
Start below the model.
Mark canonical datasets
Make the trusted source for common business questions explicit. Do not make the agent infer authority from table names.
Mark deprecated, experimental, and scratch datasets
Deprecated tables should remain visible as deprecated. Scratch tables should not look production-grade because their names are convenient.
Track ownership and freshness
Every important dataset should have an owner and a freshness expectation. Ownership gives uncertainty somewhere to go.
Capture lineage and downstream usage
Expose upstream jobs, downstream dashboards, dependent metrics, and column-level lineage where possible.
Document grain, primary keys, and safe joins
Many silent analytical failures come from joining at the wrong grain. Make safe join paths explicit.
Expose quality signals to the agent
Freshness failures, schema changes, row-count anomalies, missing-value checks, and failed assertions should be available at retrieval, planning, or answer time.
Rank historical queries by trust
Prefer production dashboards, repeated queries, and owner-reviewed examples over ad hoc exploration.
Document metric definitions
A metric should have a definition, owner, dimensions, filters, caveats, and valid time grains. Otherwise, the agent will invent a working definition from nearby columns.
References
OpenAI, “Inside OpenAI’s in-house data agent”, primary public case study for scale, table discovery, context layers, silent analytical failure modes, permissions, and evals.
ByteByteGo, “How OpenAI Built Its Data Agent”, secondary interpretation for the foundation-first framing, context assembly, trusted query ranking, and tool curation.
dbt model contracts, useful for the distinction between shape contracts and data tests.
dbt MetricFlow and Semantic Layer, useful for metric definitions, semantic models, and semantic graph framing.
OpenLineage object model, useful for lineage as runtime and design metadata around jobs and datasets.
Soda data observability, useful for data quality signals such as schema changes, row counts, freshness timestamps, missing values, and distribution shifts.
Recap
A data agent does not become reliable because the model is better.
It becomes reliable because the data platform makes meaning, quality, and ownership visible before the model reasons over it.
Schemas matter, but schemas describe shape.
Production trust needs more: canonical datasets, deprecation status, owners, freshness, lineage, grain, quality signals, metric definitions, trusted query patterns, and caveats.
The model cannot infer a clean source of truth from a messy platform.
It will choose something.
The question is whether the platform gives it enough evidence to choose correctly.
If the foundation does not encode trust, the agent will infer it.
That is where plausible wrong answers come from.
What comes next
Part 2 asked which foundation signals need to exist.
Part 3 asks which of those signals the agent should actually see for a given question.
That is context assembly.
The next post will cover how table usage, human annotations, institutional knowledge, memory, code-enriched context, and runtime checks become the payload the model reasons over.
Because the model does not reason over your warehouse.
It reasons over the context you put in front of it.
The Data Agent series index
If you are new to the series, start with Part 1:

It sets up the core frame: a data agent is not text-to-SQL. It is a governed analysis loop that resolves meaning, finds trusted data, executes safely, validates results, and returns evidence.
Subscribe to follow the next parts as we go deeper into context assembly, code-derived meaning, tools, trust, permissions, and evals.
If you are building a data agent, analytics agent, BI copilot, warehouse assistant, or metrics system, where does the foundation break first?
Ownership, freshness, lineage, canonical datasets, metric definitions, deprecated tables, or data quality signals?
Comment below. I’d love to compare notes.
References
OpenAI, “Inside OpenAI’s in-house data agent”
Primary public case study for data-agent scale, table discovery, context layers, silent analytical failure modes, permissions, and evals.ByteByteGo, “How OpenAI Built Its Data Agent”
Secondary interpretation for the foundation-first framing, context assembly, trusted query ranking, and tool curation.dbt, “Model contracts”
Useful for the distinction between dataset shape, contracts, and validation.dbt, “About MetricFlow”
Useful for semantic models, metric definitions, and the semantic graph framing.OpenLineage, “Object Model”
Useful for lineage as runtime and design metadata around jobs, runs, and datasets.Soda, “Data Observability”
Useful for data quality and observability signals such as schema changes, row counts, freshness, missing values, and distribution shifts.DataHub, “Freshness Assertions”
Useful for freshness expectations, monitoring, and why stale data can break downstream analytics trust.