
The Agent Stack - Part 1: A Systems Map of Modern Agent Infrastructure
Why “agent” has become too overloaded to be useful, and why it’s really a stack of layers

A Slack message lands at 11:27 PM.
The model is the part we talk about. But before anything useful happens, the system has to answer less glamorous questions. Which session owns this turn? What context belongs on the hot path? Which tools are visible? If a side effect follows, who approved it?
We usually call that whole chain an agent.
That word now hides more than it explains.
This post is not a market map. It is a systems map. My goal is to define a useful v1 of the stack that turns model output into bounded action, then use that map to make the rest of the series easier to reason about.
The word stopped helping
“Agent” used to be loose but still usable.
Now it gets applied to provider APIs, workflow runtimes, browser operators, memory systems, tracing products, eval platforms, and everything in between. Those systems touch each other, but they do not own the same job.
That is the real problem.
Once the same label covers state ownership, orchestration, capability exposure, execution, and operator feedback, the label stops telling you anything important. It stops telling you where authority lives. It stops telling you where state lives. It stops telling you what actually failed when something goes wrong.
The useful unit is no longer the agent. It is the stack around the model.
That is the frame I want for this series.
Not because the stack is perfect. Not because the ecosystem is settled. Just because it is a better unit of analysis than one overloaded word.
Why define the stack now
My read is that the stack is worth defining now because packaging is collapsing faster than architecture.
More products now span multiple layers at once. A provider API may bundle stateful continuation, tools, hosted execution, and tracing. A runtime may also expose memory patterns, interrupts, and long-running workflows. A browser product may look like a tool layer from one angle and an execution layer from another.
That bundling is useful. It is also confusing.
If you leave the layers unnamed, everything starts to look like one big blob called “agent infrastructure.” Then every failure gets described the same way. The agent forgot. The agent hallucinated. The agent did the wrong thing.
Usually that is true in the least useful sense possible.
The more useful question is: which layer failed?
Did the system resolve the wrong session? Assemble the wrong context? Expose the wrong capability? Approve the wrong action? Retry the wrong step? Record too little evidence to explain what happened later?
That is why I want a stack model.
Not to tidy up the market. To make real systems easier to reason about.
A systems map of the stack
I do not think about the stack as ten equal boxes on a poster.
My read is that the cleanest v1 is not a pure vertical stack. It is a request path, wrapped by trust and operator layers, with approvals appearing where side effects become real, all sitting on top of shared infrastructure.
If you remember one picture from this post, make it this one.
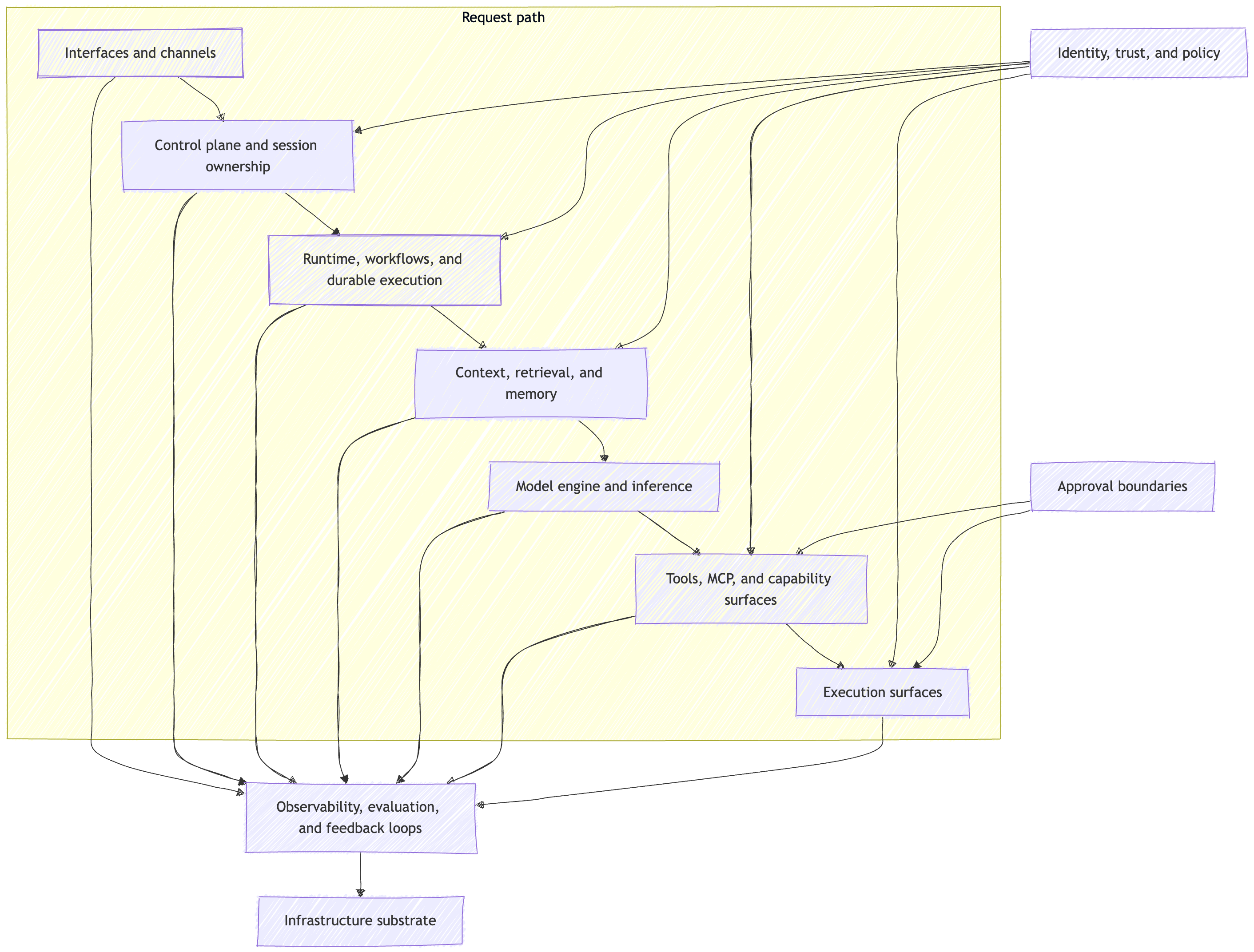
That picture gives me the ten layers I want to use in the series:
Interfaces and channels
Control plane and session ownership
Runtime, workflows, and durable execution
Model engine and inference
Context, retrieval, and memory
Tools, MCP, and capability surfaces
Execution surfaces
Identity, trust, policy, and approvals
Observability, evaluation, and feedback loops
Infrastructure substrate
The list matters, but the list is not the main idea.
The main idea is ownership.
Which layer owns the run?
Which layer owns the working set for this turn?
Which layer owns callable capability?
Which layer owns the side effect?
Which layer owns the evidence afterward?
Once you can answer those questions, the ecosystem gets easier to reason about very quickly.
If you want a few landmarks, use them lightly. Some systems sit closer to inference and hosted tools. Some sit closer to runtime and durable execution. Some sit at the capability seam. Some focus on memory, some on browsers and sandboxes, some on traces and evals.
Those examples are helpful.
They are not the argument.
Products can span multiple layers. The layers still matter.
From event to action
Let’s go back to that Slack message.
A user asks the system to send updated pricing to a customer.
That sounds like one task. It is not one layer.
First, the interface layer receives the event. Slack, email, voice, browser, webhook, IDE, API. This is where work enters the system.
Then the control plane decides what this event belongs to. Which user? Which session? Which run? Which policy attachment? Which state record is the source of truth?
After that, the runtime takes over. It decides how the run proceeds. It may assemble context, call a model, invoke a tool, wait on an approval, retry a step, or resume from durable state after a delay or failure.
The model layer does one job. It turns the prepared request into output. Text, structured output, tool-call intent, maybe another step in the loop. It does not own the whole system around that call.
Then come the capability and action layers. Tools and MCP expose what the model may ask for. Execution surfaces are where the system actually acts: browser, shell, code executor, database client, filesystem, remote worker, external API.
That distinction matters more than it looks.
A tool tells the model what it may ask for. The execution surface determines what actually happens.
Finally, the operator loop answers a different class of question. Not what should happen next, but what happened, was it good, and how do we improve it? That is observability, evaluation, and feedback. Traces, logs, transcripts, state snapshots, regression checks, release decisions.
One request path makes this clearer than another list can.
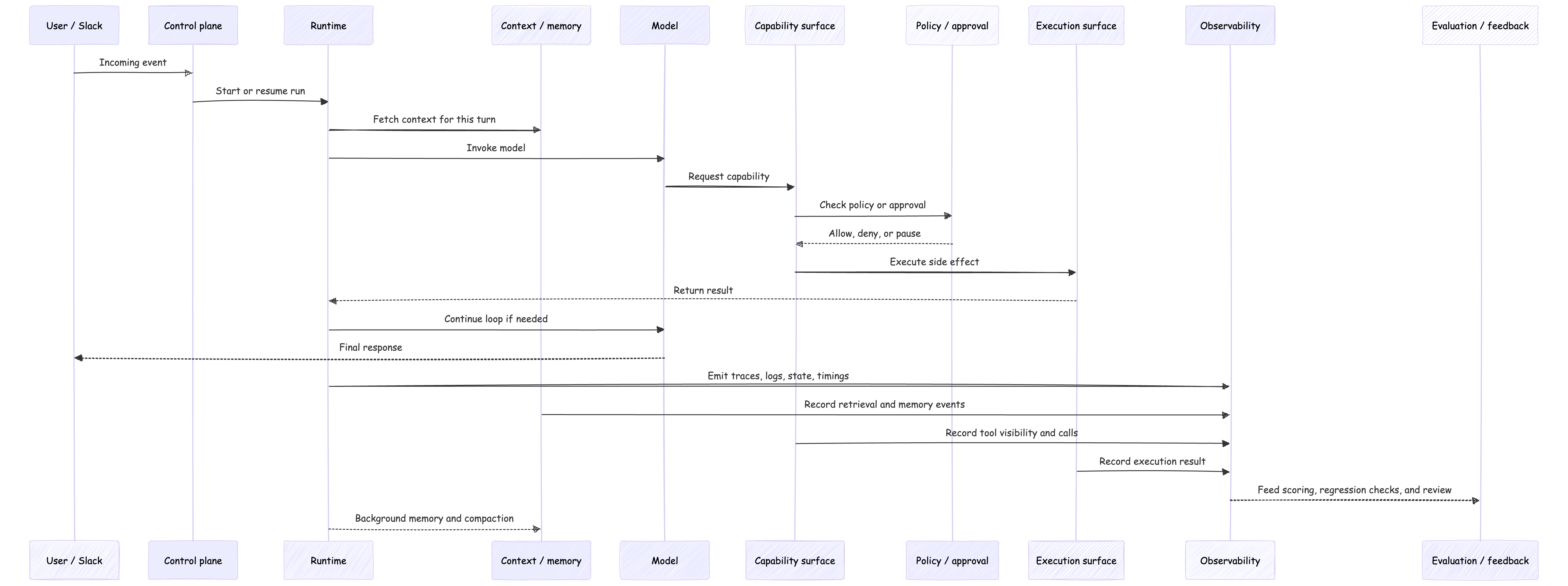
That picture is why I keep saying this is a stack, not a blob.
The model is in the middle. It is important. It is also surrounded by layers that decide what it sees, what it can ask for, what actually gets executed, and what survives afterward as evidence.
The boundaries that matter
This is the center of the article.
The stack is useful because it forces boundary clarity.
Session is not authorization.
A session tells you which interaction owns a turn. Authorization tells you who is allowed to read, change, or act. Those are different boundaries, and they fail differently.
Transcript is not context.
The transcript is the durable record. Context is the carefully assembled payload for one turn. Treating them as the same thing is how hot paths get bloated and relevance gets worse.
Memory is not learning.
In this series, memory means durable state persisted outside the model and re-injected later. Not weight updates. Not magic. State ownership plus rehydration.
Capability is not execution.
A tool schema, connector, or MCP endpoint tells the model what it may request. It does not tell you where the side effect runs, what the blast radius is, or whether a human needs to approve it first.
Approval is not isolation.
A human approval gate decides whether an action should proceed. A sandbox or isolated browser decides what the action can do once it proceeds. Sensitive systems usually need both.
Observability is not evaluation.
Observability gives you evidence. Evaluation turns evidence into judgment. One tells you what happened. The other tells you whether it was good enough.
“Same label, different authority” is a useful way to think about the current ecosystem.
We keep reusing the same words across layers that own very different kinds of risk.
A second picture helps here.
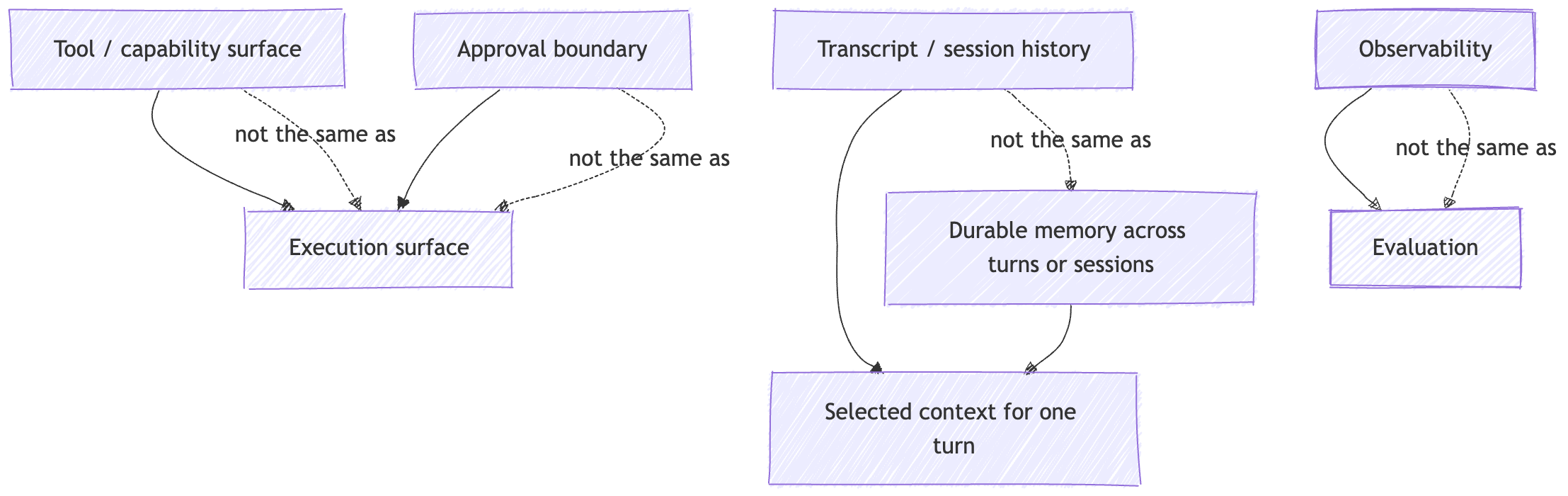
If you keep those distinctions intact, the system gets easier to debug, safer to operate, and easier to explain.
If you collapse them, things start to feel haunted.
What breaks when layers collapse
This is where a stack model earns its keep.
If you treat the transcript as memory, your hot path keeps paying for context it no longer needs. Cost rises. Latency rises. Relevance often gets worse anyway. You overpay and under-remember at the same time.
If you treat a tool schema as permission, you eventually let the system act without clearly deciding whether it should act. Capability exposure, execution authority, and approval policy collapse into one vague idea of “the agent can do this.”
If you treat the model API as the runtime, every orchestration failure gets misdiagnosed as model quality. Retries, resumptions, duplicate side effects, stale context, bad handoffs, wrong waits. All of it becomes “the agent was weird.”
If you treat observability and evaluation as the same thing, you get anecdotes instead of a release process. You can replay a trace and still have no disciplined answer to whether the system improved.
If you treat memory as a vector database, you reduce a whole lifecycle to one storage primitive. Retrieval matters. So do extraction, consolidation, provenance, forgetting, timing, and scope. The storage engine is not the whole layer.
If you treat a framework as the whole stack, you inherit its abstractions as if they were the architecture itself. That is the quickest way to confuse product boundaries with system boundaries.
None of these are just naming errors.
They are architecture errors.
They change what state gets persisted, what authority gets exposed, what gets blamed during incidents, and what evidence survives after the run is over.
Builder checklist
If you are building in this space, these are the first questions I would want answered:
Name the source of truth for session ownership.
Decide what belongs on the hot path and what belongs in background flows.
Separate transcript, context, and memory in both code and language.
Separate capability exposure from execution authority.
Put approvals where side effects become real.
Trace runs, then evaluate them with explicit criteria.
Choose durable execution based on retry, wait, and resume needs, not demo convenience.
That is a better starting point than “which agent framework should I use?”
Not because frameworks do not matter.
Because those questions matter first.
Recap
An agent is not one thing.
It is a stack of layers that turns model output into bounded action.
That is the whole argument of Part 1. Not that this map is final. Not that every product slices the layers the same way. Just that builders need a better unit of analysis than “agent,” and right now the stack is the most useful one I know.
Once you stop asking “which agent platform is this?” and start asking “which layer owns the run, which layer owns the side effect, and which layer owns the evidence,” the ecosystem gets easier to reason about.
That is the point of the map.
What comes next
In the next part, I’ll start lower than most agent writing starts: infrastructure, models, and inference.
Every agent app inherits the constraints of its substrate.
That is where I want to go next.
The Agent Stack v1
Part 1: A Systems Map of Modern Agent Infrastructure
Part 2: Infrastructure, Models, and Inference
Part 3: Control Planes, Sessions, and State Ownership
Part 4: Runtimes, Workflows, and Durable Execution
Part 5: Context, Retrieval, and Memory
Part 6: Tools, MCP, and Capability Surfaces
Part 7: Execution Surfaces, Identity, and Approval Boundaries
Part 8: Observability, Evaluation, and Production Feedback Loops
References
OpenAI Responses API and Agents SDK docs, used for the current provider-side view of stateful continuation, sessions, approvals, and tracing.
Model Context Protocol docs, especially Roots and Sampling, used for the capability-surface and human-control framing around MCP.
LangGraph official docs, used for runtime, persistence, checkpoints, interrupts, memory, and durable execution framing.
Playwright BrowserContext docs, used for the execution-surface and isolation examples.
Temporal docs, used for the durable execution and resume-after-failure framing.
great info as usual Vinoth!
Layer 8 (identity, trust, policy, approvals) is the one that actually breaks in production. Ran into it building an agent marketplace, the trust layer I defined for my agent working inside my own systems didn't transfer when that agent started transacting with external services.
Your framing of "tool tells the model what it may ask for, execution surface determines what actually happens" is exactly right. But there's a gap between the tool layer and the trust layer in your stack: who governs which agents are allowed to be on the execution surface at all? In a marketplace context that's a verification and onboarding problem nobody's solved yet.
The layer 8 section feels like it assumes a closed system. What does trust policy look like when you're the third party, not the platform owner?